注意:您可能对DocFetcher Pro感兴趣,它是DocFetcher的商业增强版,拥有更多功能,或者DocFetcher Server,DocFetcher的商业版本,支持多用户和Web界面。了解更多。
描述
DocFetcher是一个开源桌面搜索应用程序:它允许您搜索计算机上的文件内容。— 您可以将其视为Google的本地文件。该应用程序在Windows,Linux和macOS上运行,并在Eclipse Public License下提供。
基本用法
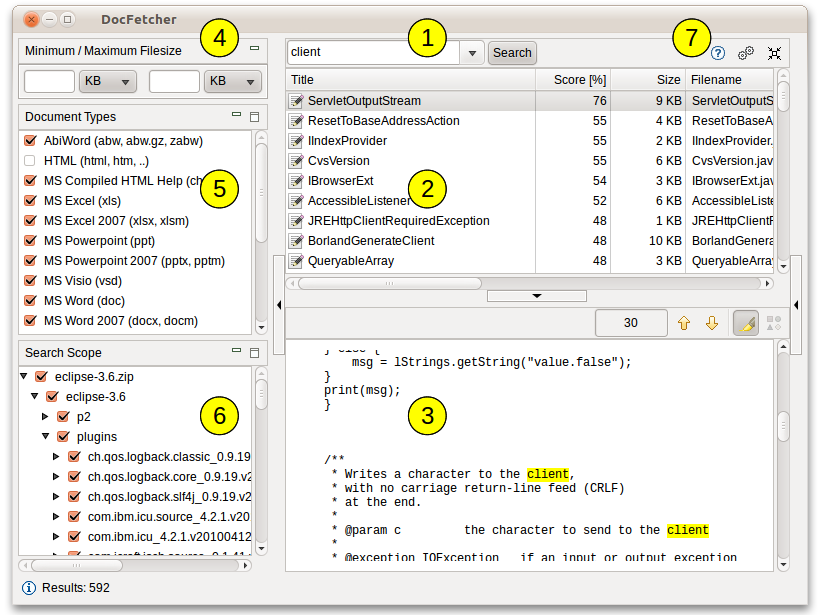
下面的屏幕截图显示了主用户界面。查询在(1)的文本字段中输入。搜索结果显示在结果窗格中的(2)处。(3)中的预览窗格显示了结果窗格中当前所选文件的纯文本预览。文件中的所有匹配项都以黄色突出显示。
您可以按最小和/或最大文件大小(4),按文件类型(5)和按位置(6)过滤结果。(7)处的按钮分别用于打开手册,打开首选项和最小化程序到系统托盘中。
DocFetcher要求您为要搜索的文件夹创建所谓的索引。下面将详细介绍索引及其工作原理。简而言之,索引允许DocFetcher非常快速地(以毫秒为单位)找出哪些文件包含特定的单词集,从而大大加快了搜索速度。以下屏幕截图显示了DocFetcher用于创建新索引的对话框:
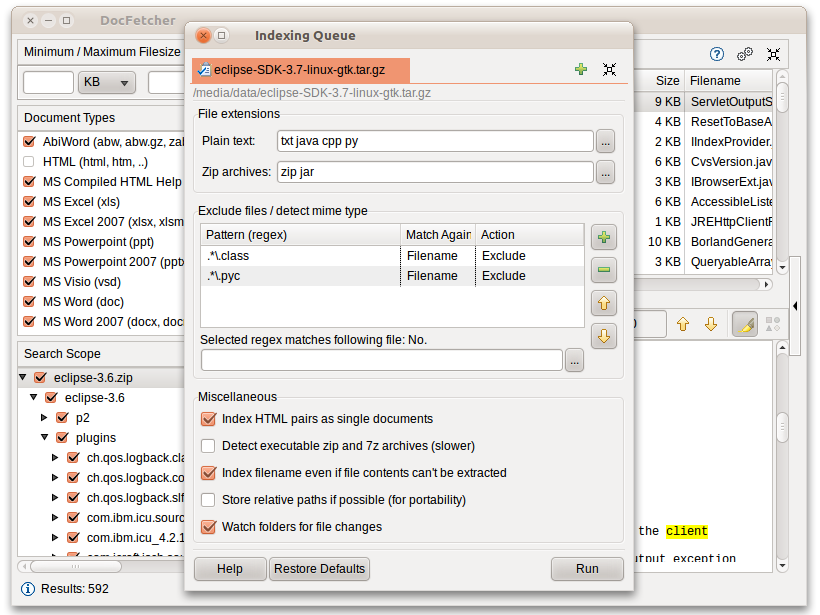
单击此对话框右下角的“运行”按钮可启动索引编制。索引过程可能需要一段时间,具体取决于要编制索引的文件的数量和大小。一个好的经验法则是每分钟200个文件。
虽然创建索引需要时间,但每个文件夹只需执行一次。此外,在文件夹内容发生变化后更新索引比创建它快得多 — 它通常只需要几秒钟。
主要特点
- 便携版本:DocFetcher提供可在Windows、Linux和macOS上运行的便携版本。这些便携版本允许您创建便携式文档存储库:一个完全索引且完全可搜索的重要文档存储库,您可以自由移动。这意味着您可以将其随身携带在USB驱动器上,打包用于存档目的,放入加密卷中,通过云端驱动器在多台计算机之间同步,甚至上传并与世界其他地方共享。
- Unicode支持:DocFetcher为所有主要格式提供坚如磐石的Unicode支持,包括Microsoft Office,OpenOffice.org,PDF,HTML,RTF和纯文本文件。
- 存档支持:DocFetcher支持以下存档格式:zip,7z,rar和整个tar。*系列。可以自定义zip存档的文件扩展名,允许您根据需要添加更多基于zip的存档格式。此外,DocFetcher可以处理无限制的存档嵌套(例如,包含带有rar存档的7z存档的zip存档......等等)。
- 在源代码文件中搜索:可以自定义DocFetcher识别纯文本文件的文件扩展名,因此您可以使用DocFetcher搜索任何类型的源代码和其他基于文本的文件格式。(这与可自定义的zip扩展相结合非常有效,例如,用于在Jar文件中搜索Java源代码。)
- Outlook PST文件:DocFetcher允许搜索Outlook电子邮件,Microsoft Outlook通常存储在PST文件中。
- HTML对的检测:默认情况下,DocFetcher会检测HTML文件对(例如名为“foo.html”的文件和名为“foo_files”的文件夹),并将该对视为单个文档。这个功能一开始看起来似乎没用,但事实证明,当你处理HTML文件时,这会大大提高搜索结果的质量,因为HTML文件夹中的所有“混乱”都会从结果中消失。
- 基于正则表达式的文件从索引中排除:您可以使用正则表达式从索引中排除某些文件。例如,要排除Microsoft Excel文件,可以使用如下的正则表达式:
.*\.xls - Mime类型检测:您可以使用正则表达式为某些文件启用“mime-type detection”,这意味着DocFetcher将尝试检测其实际文件类型,而不仅仅是通过查看文件名,还可以通过偷看文件内容。这对于文件扩展名错误的文件很方便。
- 强大的查询语法:除了“OR”,“AND”和“NOT”之类的基本结构之外,DocFetcher还支持以下内容:通配符,短语搜索,模糊搜索(“查找类似单词“),邻近搜索(”这两个单词应该相距最多10个单词“),提升(”增加文档的权重“)
支持的文档格式
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 及更新版本 (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, ...)
- TXT和其他纯文本格式(可自定义)
- 富文本文件 (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
设计理念
DocFetcher的设计遵循以下原则:
无废话:DocFetcher的用户界面设计为整洁、无垃圾。系统中不会安装任何无用的东西。
隐私:DocFetcher绝对不会收集您的私人数据。您可以随时查看源代码。
仅对您需要的内容进行索引:其他搜索软件默认索引整个硬盘驱动器 — 也许是为了迎合"愚蠢"用户,替他们做决定,或者收集更多用户数据。而DocFetcher则相反,默认不索引任何内容,将选择要索引的数据的权力留给用户。这基于这样的观察:索引整个硬盘驱动器通常是对索引时间和磁盘空间的巨大浪费,还会导致搜索结果中充斥着不相关的文件。
索引如何工作
本节试图基本了解索引是什么以及它是如何工作的。
文件搜索的天真方法:文件搜索的最基本方法是在执行搜索时逐个访问特定位置的每个文件。这适用于filename-only搜索,因为分析文件名非常快。但是,如果要搜索文件的contents,它将无法正常工作,因为全文提取是比文件名分析更昂贵的操作。
基于索引的搜索:这就是为什么作为内容搜索者的DocFetcher采用一种称为索引的方法:基本思想是人们需要搜索的大多数文件(例如,超过95%)都是很少修改或根本不修改。因此,不是在每次搜索的每个文件上进行全文提取,而是对所有文件执行文本提取只需,并从所有提取的文本创建所谓的index。这个索引有点像字典,它允许通过它们包含的单词快速查找文件。
电话簿类比:作为类比,考虑在电话簿中查找某人的电话号码(“索引”),而不是拨打每个可能的电话号码,以查明是否有效在另一端的人是你正在寻找的人。— 通过电话呼叫某人并从文件中提取文本都可以被视为“昂贵的操作”。此外,人们不经常更改电话号码的事实类似于计算机上的大多数文件很少被修改的事实。
索引更新:当然,索引仅反映索引文件创建时的状态,而不一定是文件的最新状态。因此,如果索引没有保持最新,您可能会得到过时的搜索结果,就像电话簿过时一样。但是,如果我们可以假设大多数文件很少被修改,那么这应该不是什么大问题。此外,DocFetcher能够自动更新其索引:(1)当它运行时,它会检测更改的文件并相应地更新其索引。(2)当它没有运行时,后台的一个小守护进程将检测到变化并保留一个要更新的索引列表; 然后,DocFetcher将在下次启动时更新这些索引。








