Примітка: Вас може зацікавити DocFetcher Pro, комерційний старший брат DocFetcher з більшою кількістю функцій, або DocFetcher Server, комерційний родич DocFetcher з підтримкою багатокористувацького режиму та веб-інтерфейсом. Дізнатися більше.
Опис
DocFetcher є відкрито-джерельним настільним застосунком пошуку: Він дозволяє вам шукати вміст файлів на вашому комп'ютері. — Ви можете думати про нього, як про Google для ваших локальних файлів.. Цей застосунок працює на Windows, Linux та macOS, і доступний під Eclipse Public License.
Базове використання
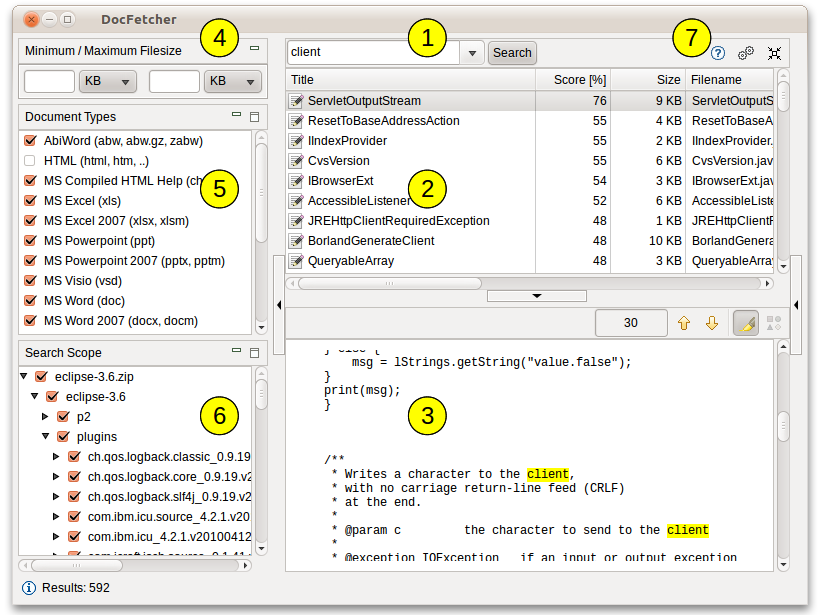
Екранознімок нижче показує головний інтерфейс користувача. Запити уводяться у текстове поле (1). Результати пошуку показуються у панелі результатів (2). Панель передогляду (3) показує лише текстовий передогляд файлу, що поточно вибраний у панелі результатів. Усі відповідності у цьому файлі підсвічуються жовтим.
Ви можете фільтрувати результати за мінімумом та/або максимумом розміру файлу (4), за типом файлу (5) та за розміщенням (6). Кнопки (7) використовуються для відкриття цього підручника, відкриття уподобань та мінімізування програми у системний трей, відповідно.
DocFetcher вимагає, щоб ви створили так звані індекси для тек, в яких ви хочете шукати. Що таке індексування та як воно працює, пояснюється більш детально нижче. У кількох словах, індекс дозволяє DocFetcher'у знаходити дуже швидко (за кілька мілісекунд) те, які файли містять певний набір слів, таким чином значно пришвидшуючи пошуки. Наступний екранознімок показує діалог DocFetcher'а для створення нових індексів:
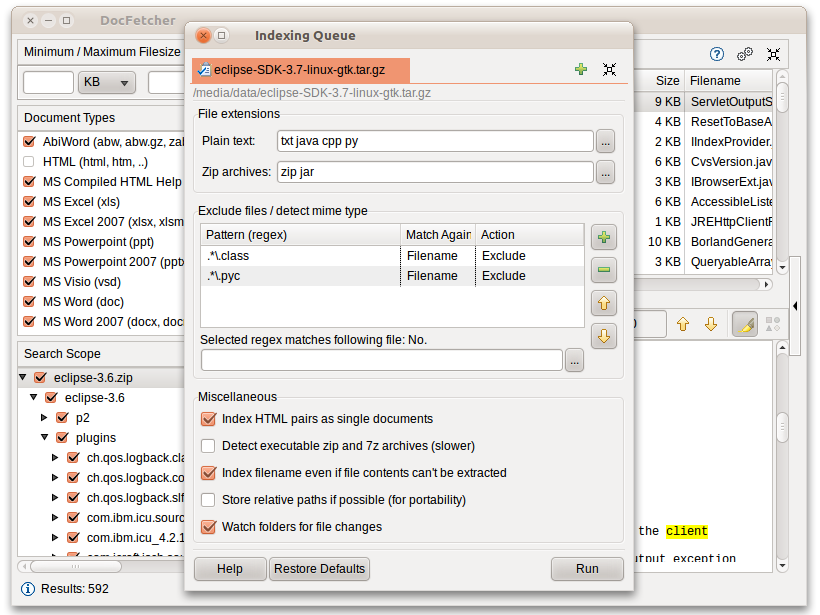
Клацання кнопки "Пуск" внизу справа цього діалогу запускає індексування. Процес індексування може займати деякий час, залежно від кількості та розмірів файлів, що індексуються. Хороше емпіричне правило - 200 файлів за хвилину.
Хоча створення індексу займає деякий час, воно робиться лише один раз для кожної теки. Також, оновлення індексу після того, як вміст теки змінено, набагато швидше, ніж його створення — перше зазвичай займає лише кілька секунд.
Помітні особливості
- Портативні версії: Існують портативні версії DocFetcher'а, які працюють на Windows, Linux та macOS відповідно. Ці портативні версії дозволяють вам створити портативний репозиторій документів: повністю індексований та повністю здатний до пошуку репозиторій всіх ваших важливих документів, котрий ви можете вільно переміщати. Це означає, що ви можете носити його з собою на USB-накопичувачі, упакувати для архівних цілей, помістити у зашифрований том, синхронізувати між кількома комп'ютерами через хмарне сховище або навіть завантажити та поділитися ним з рештою світу.
- Підтримка Unicode: DocFetcher поставляється з міцною підтримкою Unicode для усіх головних форматів, включаючи Microsoft Office, OpenOffice.org, PDF, HTML, RTF та файли звичайного тексту.
- Підтримка архівів: DocFetcher підтримує наступні формати архівів: zip, 7z, rar та все сімейство tar.*. Розширення файлів для архівів zip можна налаштовувати, що дозволяє вам додавати ще більше базованих на zip форматів архівів при потребі. Також, DocFetcher може обробляти безмежне вкладення архівів (наприклад, архів zip містить у собі архів 7z, котрий містить архів rar... і так далі).
- Пошук у файлах джерельного коду: Розширення файлів, за якими DocFetcher розпізнає файли зі звичайним текстом, можуть бути налаштовані, звідси ви можете використовувати DocFetcher для пошуку у будь-якому виді джерельного коду та інших базованих на тексті форматах файлів. (Це працює досить добре у комбінації з налаштовуваними розширеннями для zip, наприклад, для пошуку джерельному коді Java всередині файлів Jar.)
- Файли Outlook PST: DocFetcher дозволяє пошук в е-листах Outlook, які Microsoft Outlook типово збергіає у файлах PST.
- Виявлення пар HTML: Стандартно, DocFetcher виявляє пари файлів HTML (наприклад, файл з іменем "foo.html" та теку з назвою "foo_files"), та обробляє цю пару, як єдиний документ. Ця особливість може здаватися спочатку некорисною, але виявляється, що це значно підвищує якість результатів пошуку, коли ви маєте справу з файлами HTML, оскільки увесь "безлад" всередині тек HTML зникає з результатів.
- Базоване на регулярних виразах виключення файлів з індексування: Ви можете використовувати регулярні вирази для виключення певних файлів з індексування. Наприклад, для виключення файлів Microsoft Excel, ви можете вжити такий регулярний вираз:
.*\.xls - Виявлення типу mime: Ви можете використовувати регулярні вирази для "виявлення типу mime" для певних файлів, тобто DocFetcher буде намагатися виявляти їх фактичні файлові типи не просто дивлячись на ім'я файлу, але також заглядаючи у вміст цих файлів. Це стає в нагоді для файлів, що мають неправильне файлове розширення.
- Потужний синтаксис запиту: Додатково до базових конструкцій, як
OR,ANDтаNOT, DocFetcher також підтримує серед інших: знаки підстанови, пошук фраз, нечіткий пошук ("знайти слова, що є подібними до..."), пошук за близькістю ("ці два слова повинні бути на відстані максимум 10 слів одне від одного"), підвищення пріоритету ("підвищити пріоритет документів, що містять...")
Підтримувані формати документів
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 і новіше (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, ...)
- TXT та інші формати звичайного тексту (налаштовувано)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Філософія дизайну
Дизайн DocFetcher слідує цим принципам:
Свобода від безладу: Інтерфейс користувача DocFetcher'а розроблений так, щоб бути вільним від хаосу та безладу. Жодного безкорисного мотлоху не інсталюється у вашій системі.
Конфіденційність: DocFetcher не збирає ваші особисті дані, крапка. Будь ласка, перевірте джерельний код.
Індексування лише того, що вам потрібно: Інше програмне забезпечення для пошуку індексує весь ваш жорсткий диск за замовчуванням — можливо, щоб пристосуватися до "німих" користувачів, позбавляючи їх вибору, або щоб збирати більше даних користувача. DocFetcher, з іншого боку, не індексує нічого за замовчуванням, залишаючи вибір даних для індексування користувачам. Це базується на спостереженні, що індексування цілих жорстких дисків зазвичай є величезною втратою часу на індексацію та дискового простору, що також призводить до захаращення результатів пошуку нерелевантними файлами.
Як працює індексування
Цей підрозділ пояснює, що таке індексування та як воно працює.
Наївний підхід до пошуку файлів: Найбільш базовий підхід до пошуку файлів є просто відвідати кожен файл у певній локації один за одним при здійсненні шукання. Це працює досить добре для пошуку лише за іменами файлів, оскільки аналізування імен файлів є дуже швидким. Проте, це не працюватиме так добре, якщо ви хочете шукати вміст файлів, оскільки витягнення повного тексту є набагато більш витратною операцією, ніж аналіз імен файлів.
Базований на індексуванні пошук: Ось чому DocFetcher, будучи шукачем вмісту, застосовує підхід, відомий як індексування: Базова ідея полягає у тому, що більшість файлів, які люди повинні шукати (схоже, більше ніж 95%), модифікуються дуже рідко або взагалі не змінюються. Тому, чим робити повне витягнення тексту з кожного файлу при кожному пошуку, набагато більш ефективно здійснювати витягнення тексту з усіх файлів лише один раз та створити так званий індекс з усього витягненого тексту. Цей індекс є певним видом словника, що дозволяє швидко шукати файли за словами, які вони містять.
Аналогія з телефонною книгою: Як аналогія, подумайте, наскільки ефективніше шукати чийсь телефонний номер у телефонній книзі ("індекс"), порівняно з телефонуванням на кожен можливий номер телефону лише для того, щоб дізнатися, чи є потрібна людина на іншому кінці, яку ви шукаєте. — Зателефонувати комусь по телефону і витягти текст з файлу можна вважати "витратними операціями". Також, той факт, що люди не часто змінюють свої телефонні номери, аналогічний тому, що більшість файлів на комп'ютері рідко коли-небудь змінюються.
Оновлення індексу. Звичайно, індекс лише відбиває стан індексованих файлів, коли він був створений, і не обов'язково останній стан файлів. Звідси, якщо індекс не оновлюється, можна отримати застарілі результати пошуку, так само, як телефонна книга може стати застарілою. Однак, це не повинно бути проблемою, якщо ми можемо припустити, що більшість файлів рідко змінюються. Додатково, DocFetcher здатний автоматично оновлювати свої індекси: (1) Коли він працює, він виявляє змінені файли і відповідно оновлює свої індекси. (2) Коли він не запущений, маленький демон у фоновому режимі виявить зміни та збереже список індексів для оновлення; DocFetcher потім оновить ці індекси під час наступного запуску.








