Примечание: Вас может заинтересовать DocFetcher Pro, коммерческий старший брат DocFetcher с большим количеством функций, или DocFetcher Server, коммерческий родственник DocFetcher с поддержкой нескольких пользователей и веб-интерфейсом. Узнать больше.
Описание
DocFetcher – это приложение с открытым исходным кодом, позволяющее вам совершать поиск по содержимому файлов на вашем компьютере. — Это как Google, но только для локальных файлов. Приложение работает на Windows, Linux и macOS. Распространяется по лицензии Eclipse Public License.
Как использовать?
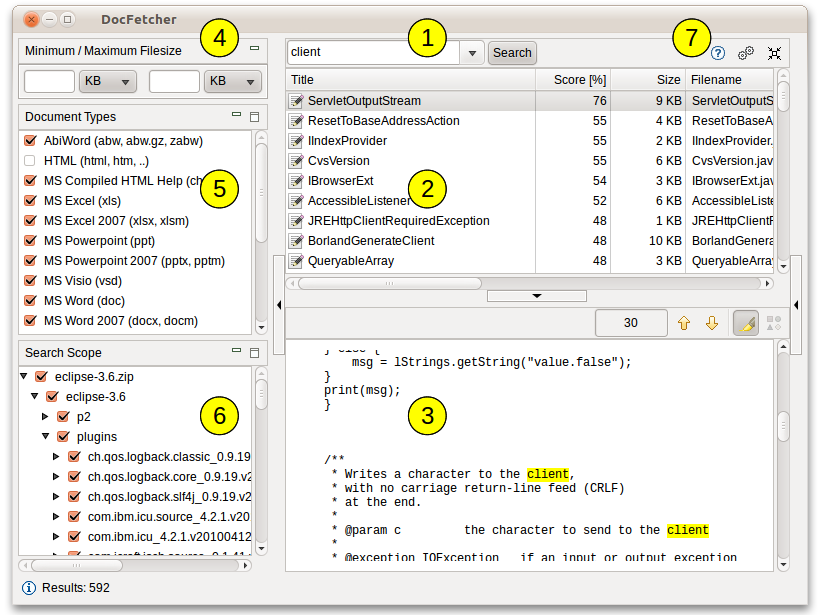
Приведённый ниже скриншот отображает основной пользовательский интерфейс программы. Запросы вводятся в текстовое поле (1). Результаты поиска отображаются в панели результатов (2). В поле предпросмотра (3) можно увидеть текстовое содержание файла, выделенного в панели результатов. Все совпадения выделены жёлтым.
Вы можете фильтровать результаты, указав минимальный или максимальный размер файла (4), тип файла (5) или его расположение (6). Кнопки, отмеченные цифрой (7), используются для вызова руководства пользователя, настроек и сворачивания программы в трей.
Для работы DocFetcher необходимо проиндексировать те папки, в которых вы хотите осуществлять поиск. Что такое индексация и как она работает подробнее описано ниже. Вкратце, индекс позволят DocFetcher быстро (буквально за несколько мгновений) определить, в каких файлах содержится определённый набор слов. Соответственно, скорость поиска увеличивается. Данный скриншот показывает диалог DocFetcher по созданию новых индексов.
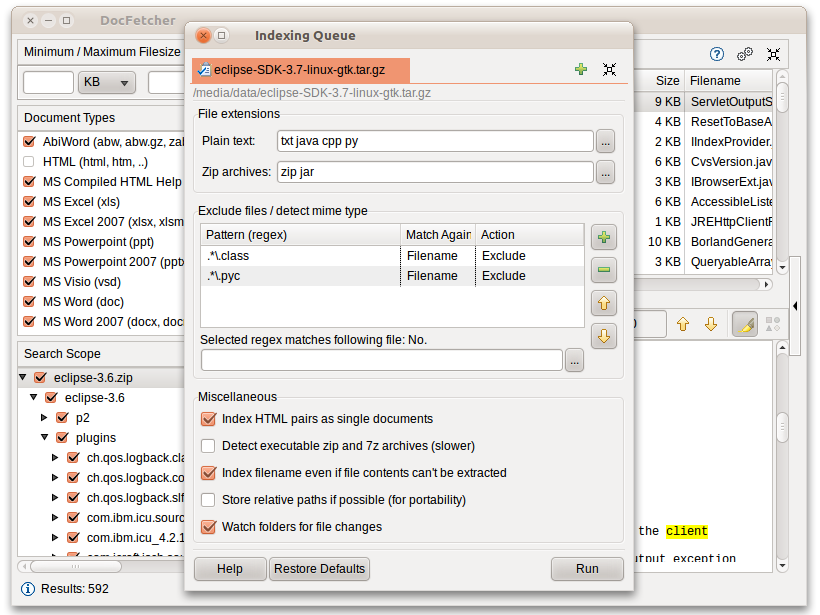
Нажатие на кнопку «Запуск» внизу этого диалогового окна запускает индексацию. Процесс индексирования может занять некоторое время, в зависимости от количества и размера файлов для индексирования. Как правило, в минуту индексируется около двухсот файлов.
Нет необходимости каждый раз индексировать заново одну и ту же папку. Обновление индекса папки после изменения её содержимого происходит гораздо быстрее. Этот процесс обычно занимает несколько секунд.
Особенности программы
- Портативные версии: Портативные версии DocFetcher работают на Windows, Linux и macOS соответственно. Эти портативные версии позволяют создать портативное хранилище документов: полностью индексированное и доступное для поиска хранилище всех ваших важных документов, которое вы можете свободно перемещать. Это означает, что вы можете носить его с собой на USB-диске, упаковать для архивных целей, поместить в зашифрованный раздел, синхронизировать между несколькими компьютерами через облачное хранилище или даже загрузить и поделиться им со всем миром.
- Поддержка Unicode: DocFetcher поддерживает Unicode для всех основных форматов файлов, включая Microsoft Office, OpenOffice.org, PDF, HTML, RTF и TXT.
- Поддержка архивированных файлов: DocFetcher поддерживает следующие форматы архивов: zip, 7z, rar, и всё семейство архивов tar.*. Список расширений файлов для zip-архивов может быть изменён, что позволит вам добавить поддержку других форматов, основанных на zip. Кроме того, DocFetcher может с лёгкостью справляться с неограниченным количеством вложенных архивов.
- Поиск в файлах исходных кодов: Расширения файлов, в которых DocFetcher распознаёт обычный текст, может быть изменён, это позволит вам использовать DocFetcher для поиска в исходном коде любого вида и других текстовых форматах. (Эта функция в сочетании с функцией изменения расширений для zip-архивов даёт хорошие результаты, например, например, вы можете осуществлять поиск в исходном коде Java внутри файлов jar)
- Файлы Outlook PST: DocFetcher позволяет осуществлять поиск по письмам Outlook, которые обычно хранятся в файлах PST.
- Определение HTML-пар DocFetcher по умолчанию определяет пары HTML-файлов (например, файл под названием «foo.html» и папка под названием «foo_files») и рассматривает их как один документ. На первый взгляд эта функция может показаться бесполезной, но на самом деле она сильно увеличивает производительность при поиске по файлам HTML, так как вся неразбериха из HTML-папок не попадает в результаты поиска.
- Исключения файлов из индекса на основе регулярных выражений: Вы можете использовать регулярные выражения, чтобы исключить определённые файлы из индекса. Например, чтобы исключить файлы Microsoft Excel, вы можете использовать такое регулярное выражение:
.*\.xls - Определение MIME-типов: вы можете использовать регулярные выражения, чтобы включить «определение MIME-типов» для определённых файлов, что будет означать, что DocFetcher будет пытаться определить тип файла не просто по названию этого файла, но и по его содержимому.
- Мощный синтаксис запросов: В дополнение к стандартным выражениям типа 'OR', 'AND' и 'NOT', DocFetcher также поддерживает шаблоны подстановки, поиск фраз, неточный поиск («найти слова, похожие на данное»), поиск по соседству («эти два слова должны находиться на расстоянии не более чем в 10 слов друг от друга»), повышение («повысить оценку документов, содержащих…»)
Поддерживаемые форматы документов
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 и новее (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, ...)
- Plain text (customizable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Философия дизайна
Дизайн DocFetcher следует этим принципам:
Отсутствие мусора: Пользовательский интерфейс DocFetcher разработан так, чтобы быть чистым и свободным от мусора. Ничего ненужного не устанавливается в вашу систему.
Приватность: DocFetcher не собирает ваши личные данные, точка. Можете свободно проверить исходный код.
Индексирование только необходимого: Другие программы поиска индексируют весь ваш жёсткий диск по умолчанию — возможно, чтобы помочь «несообразительным» пользователям, забирая у них решения, или чтобы собирать больше данных пользователей. DocFetcher, с другой стороны, индексирует ничего по умолчанию, оставляя выбор данных для индексирования пользователям. Это основано на наблюдении, что индексирование всего жёсткого диска обычно является огромной тратой времени индексирования и дискового пространства, что также приводит к засорению результатов поиска нерелевантными файлами.
Как работает индексация
Этот раздел объясняет, что такое индексация и как она работает.
Простой подход к поиску файлов: Самым простым подходом к файловому поиску является банальный перебор каждого файла в папке. Это отличное решение для поиска только по имени файла, ведь анализ названий происходит достаточно быстро. Но если вам необходим поиск по содержимому файлов, то перебор здесь не подойдёт – извлечение текста более трудоёмкая задача.
Поиск, основанный на индексе: Именно поэтому DocFetcher, выполняя поиск по содержимому, использует подход, называемый «индексация». Считается, что большинство файлов (примерно 95%), в которых пользователь осуществляет поиск, не изменяются (как минимум делается это редко). Вместо того чтобы открывать каждый файл после каждого нового поискового запроса, гораздо эффективнее было бы сделать это лишь раз. Таким образом создаётся что-то вроде словаря, который называется индексом. Он позволяет быстро находить документы по содержащимся в них словам.
Сравнение с телефонной книгой: Просто подумайте о том, насколько удобнее искать чей-то номер телефона в телефонной книге (это своеобразный индекс), по сравнению с обзвоном каждого возможного номера телефона с целью узнать, не является ли человек на другом конце провода тем, кого вы ищете. — Звонок кому-либо и извлечение текста из файла – это трудоёмкие операции. Кроме того, люди меняют свои телефонные номера не так часто. Точно так же и многие файлы на компьютере долго остаются неизменными.
Обновления индекса: Конечно, индекс отображает файлы в их состоянии на момент индексирования. А оно могло и измениться. То есть, если индекс не актуален, результаты поиска будут устаревшими. Точно так же устаревает телефонная книга. Но это не проблема. Как мы уже знаем, большинство файлов обновляется очень редко. Кроме того, DocFetcher может автоматически обновлять индексы: (1) При запуске он определяет изменённые файлы и, соответственно, обновляет их индексы. (2) Когда он не запущен, маленький фоновый процесс будет определять изменения в файлах и составлять список тех из них, которые требуют обновления индекса. DocFetcher обновит эти индексы при следующем запуске.








