Nota: Potresti essere interessato a DocFetcher Pro, il fratello maggiore commerciale di DocFetcher con più funzionalità, o DocFetcher Server, il cugino commerciale di DocFetcher con supporto multi-utente e un'interfaccia web. Maggiori informazioni.
Descrizione
DocFetcher è un programma Open Source utilizzabile per effettuare ricerche locali sul computer consentendo la ricerca del contenuto dei file ivi presenti — È possibile pensare a DocFetcher come al motore di ricerca Google applicato al proprio computer. L'applicazione gira su Windows, Linux e macOS ed è reso disponibile sotto la Eclipse Public License.
Utilizzo minimale
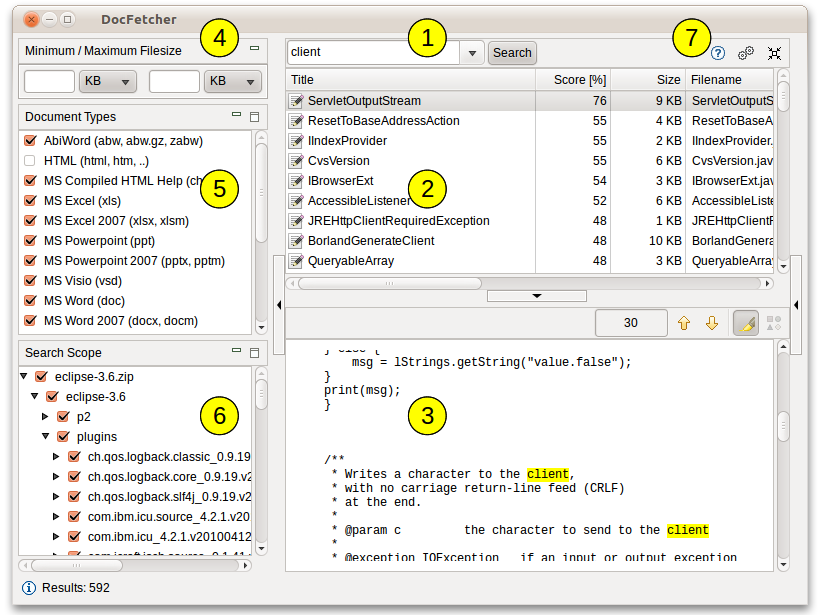
L'immagine sottostante mostra l'interfaccia-utente principale. Le stringhe da ricercare debbono essere inserite nel campo di testo contrassegnato con (1), mentre i risultati della ricerca compaiono nel pannello dei risultati (2). Il pannello di anteprima (3) mostra l'anteprima (in formato solo testo) del file correntemente selezionato nel pannello dei risultati. Tutte le corrispondenze nel contenuto vengono evidenziate in giallo.
È anche possibile filtrare i risultati della ricerca definendo la dimensione minima e massima (4), e/o il tipo (5) e/o la posizione (6) dei file. Infine i pulsanti presenti in alto a destra (7) servono rispettivamente per aprire la Guida, aprire la finestra delle Preferenze e per minimizzare il programma nell'area di notifica.
DocFetcher richiede la creazione dei cosiddetti Indici delle cartelle in cui si vogliono effettuare ricerche. Che cos'è un indice e come funziona sarà spiegato in maniera dettagliata più sotto. In breve, un indice consente a DocFetcher di trovare assai rapidamente (nell'ordine di millisecondi) quali file contengono un particolare gruppo di parole consentendo così di velocizzare enormemente le ricerche. L'immagine seguente mostra la finestra di dialogo di DocFetcher per creare nuovi indici.
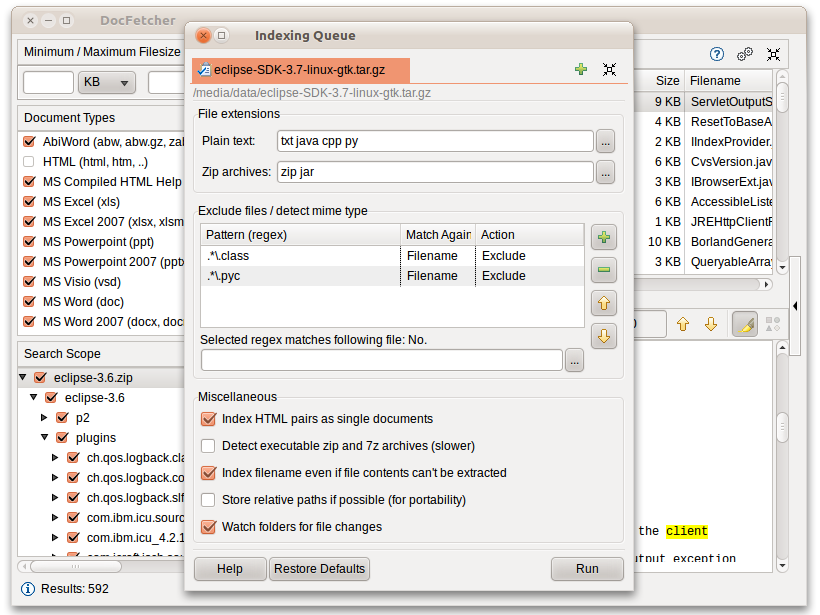
Facendo clic sul pulsante Esegui posto in basso sulla destra della finestra di dialogo, inizia l'indicizzazione. Il processo richiede un po' di tempo, in funzione del numero e delle dimensioni dei file che si vogliono indicizzare. Indicativamente si può assumere che vengano indicizzati circa 200 file al minuto.
La creazione di un indice, come detto, richiede del tempo, ma va eseguita una sola volta per ciascuna cartella. Viceversa l'aggiornamento di un indice a seguito della modifica del contenuto di una cartella è molto più veloce — generalmente impiega solo un paio di secondi.
Caratteristiche degne di nota
- Versioni portatili: esistono versioni portatili di DocFetcher che girano rispettivamente su Windows, Linux e macOS. Queste versioni portatili consentono di creare una raccolta di documenti portatili: una raccolta completamente indicizzata e ricercabile di tutti i propri documenti importanti che può essere liberamente spostata. Ciò significa che è possibile portarla con sé su una chiavetta USB, impacchettarla per scopi di archiviazione, metterla in un volume crittografato, sincronizzarla tra più computer tramite un servizio cloud, o persino caricarla online e condividerla con il resto del mondo.
- Supporto di Unicode: DocFetcher dispone di un robusto sistema di supporto di Unicode che riguarda tutti i principali formati, compresi Microsoft Office, LibreOffice/OpenOffice.org, PDF, HTML, RTF e i file di testo semplice.
- Supporto degli Archivi: DocFetcher supporta i seguenti formati di archivio: zip, 7z, rar e l'intera famiglia tar.*. Le estensioni degli archivi zip possono essere personalizzate, consentendo di aggiungere altri archivi basati su tale formato, a seconda delle necessità. Inoltre, DocFetcher può gestire una nidificazione iillimitata degli archivi (per esempio un archivio zip che contiene un archivio 7z che contiene un archivio rar ecc…).
- Ricerca nei file di codice sorgente: le estensioni dei file che DocFetcher riconosce come file di testo semplice possono essere personalizzate per cui si può usare DocFetcher per effettuare ricerche di codice sorgente all'interno di qualsiasi file di testo semplice. Questa possibilità si sposa bene anche con la personalizzazione delle estensioni zip, per esempio per cercare del codice sorgente Java all'interno dei file "jar".
- File PST di Outlook: DocFetcher consente di effettuare ricerche all'interno dei messaggi di posta elettronica gestiti da Microsoft Outlook (che tipicamente vengono memorizzati in file aventi estensione PST).
- Riconoscimento delle coppie HTML: in maniera predefinita DocFetcher riconosce le coppie HTML (per esempio un file denominato "foo.html" e la corrispondente cartella denominata "foo_files") e considera tale coppia come documento singolo. Questa caratteristica di primo acchito potrebbe sembrare non particolarmente utile, ma in realtà è molto importante per incrementare la qualità dei risultati di una ricerca che abbia a che fare con file HTML in quanto scompare dai risultati tutta quella "confusione" derivante dalla presenza di numerosi file all'interno delle cartelle HTML.
- Esclusione di file basata sulle espressioni regolari (RegEx): con DocFetcher è possibile usare le espressioni regolari per escludere dall'indicizzazione certi file. Per esempio, per escludere dall'indicizzazione tutti i file Microsoft Excel, è possibile usare un'espressione regolare come questa:
.*\.xls - Riconoscimento tipo di MIME: le espressioni regolari possono essere usate anche per attivare, per alcuni file, il riconoscimento del tipo di MIME. In questo modo DocFetcher cercherà di riconoscere gli effettivi tipi di file non guardando semplicemente al nome del file e alla sua estensione, ma anche sbirciandone il contenuto. Questa caratteristica è utile nel caso di file che abbiano una estensione "sbagliata".
- Potente sintassi di interrogazione: oltre a costrutti semplici quali
OR,ANDeNOT, DocFetcher supporta anche i caratteri jolly, la ricerca di frasi, le ricerche per analogia (fuzzy search) in cui vengono "cercate parole simili a…", le ricerche per prossimità ("queste due parole debbono essere al massimo a 10 parole di distanza l'una dall'altra"), il fattore di rafforzamento ("aumento del punteggio di congruità di quei documenti che contengono…")
Tipi di documento supportati
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 e superiori (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- Libre Office/OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, …)
- TXT e altri formati di testo semplice (personalizzabili)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- Metadati MP3 (mp3)
- Metadati FLAC (flac)
- Metadati JPEG Exif (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Filosofia di progettazione
La progettazione di DocFetcher segue questi principi:
È privo di schifezze: l'interfaccia-utente di DocFetcher è progettata per essere pulita e priva di schifezze. Niente aggiunte inutili al vostro sistema.
Privacy: DocFetcher non raccoglie i vostri dati privati, punto. Controllate pure il codice sorgente.
DocFetcher indicizza solo quanto è necessario: altri software di ricerca indicizzano l'intero hard disk per impostazione predefinita — forse per assecondare utenti "stupidi", togliendo loro le decisioni, o per raccogliere più dati degli utenti. DocFetcher invece indicizza nulla per impostazione predefinita, lasciando agli utenti la selezione dei dati da indicizzare. Ciò si basa sull'osservazione che indicizzare interi hard disk è solitamente un enorme spreco di tempo di indicizzazione e spazio su disco che porta anche a un inquinamento dei risultati di ricerca con file irrilevanti.
Come funziona l'indicizzazione
Questa sezione spiega che cos'è e come funziona il processo di indicizzazione.
Approccio semplicistico alla ricerca dei file: l'approccio più semplice quando si ricercano dei file è quello di controllare, ogni qualvolta viene eseguita una ricerca, il nome dei singoli file presenti in un certo luogo del proprio hard disk. Questo tipo di ricerca funziona bene qualora si cerchino solo i nomi dei file perché l'analisi del solo nome dei file è molto veloce. Tale tipo di ricerca però non è né molto pratico, né molto veloce se si vuole che la ricerca riguardi il contenuto dei file, poiché l'estrazione del testo è molto più dispendiosa della semplice analisi del nome dei file.
Ricerca basata sugli indici: quanto detto sopra spiega perché DocFetcher, essendo una applicazione che si occupa di ricercare i contenuti, utilizzi un approccio noto come indicizzazione. L'idea di fondo che sta alla base di tale procedura è che la maggior parte dei file di cui le persone hanno bisogno di ricercare (circa il 95% e oltre) vengono modificati solo di rado o addirittura mai. Pertanto, piuttosto di estrarre completamente il testo di ciascun file ad ogni ricerca, risulta di gran lunga più conveniente ed efficiente effettuare l'estrazione del testo di tutti i file una volta solamente, creando il cosiddetto Indice a partire da tutto il testo estratto. Questo indice risulta simile ad un dizionario in quanto consente una rapida ricerca all'interno dei diversi file attraverso la ricerca delle parole in esso contenute.
Analogia con l'elenco telefonico: si consideri quanto più efficace è cercare il numero telefonico di qualcuno/a in un elenco telefonico (l'Indice), rispetto a chiamare ogni numero telefonico possibile solo per verificare se la persona all'altro capo del filo è quella con cui si vuole effettivamente parlare. — Fare ogni volta n-mila chiamate al telefono per trovare il numero giusto o estrarre ogni volta il testo da tutti i file alla ricerca di quello/i che ci interessa/-no risulta essere un'"operazione costosa". Inoltre, analogamente al numero di telefono che la gente non cambia di frequente, anche la maggior parte dei file presenti in un computer viene modificata solo di rado se non addirittura mai.
Aggiornamento degli Indici: naturalmente un indice riflette lo stato dei file solo all'atto della sua creazione. Esso quindi non esprime necessariamente l'ultimo stato (il più recente) dei file. Pertanto, se l'indice non viene mantenuto aggiornato, si incorre nella possibilità di ottenere dei risultati di ricerca non corretti perché obsoleti, così come un elenco telefonico nel tempo diventa anch'esso obsoleto. Questo però non è un grosso problema se si assume che la maggior parte dei file vengono modificati solo raramente. Inoltre, DocFetcher è in grado di aggiornare automaticamente i propri indici: (1) mentre sta girando in quanto riconosce le eventuali modifiche dei file così da aggiornare di conseguenza i propri indici (2) se non sta girando, un piccolo demone (servizio) in background ha il compito di riconoscere le modifiche che sono intervenute nei file e mantiene un elenco degli indici che debbono essere aggiornati non appena possibile. Non appena DocFetcher verrà nuovamente eseguito, si occuperà di aggiornare quegli indici che il demone ha identificato.








