Remarque: Vous pourriez être intéressé par DocFetcher Pro, le grand frère commercial de DocFetcher avec plus de fonctionnalités, ou DocFetcher Server, le cousin commercial de DocFetcher avec support multi-utilisateurs et une interface web. En savoir plus.
Description
DocFetcher est une application Open Source pour la recherche de contenu local sur ordinateur: elle vous permet de faire des recherches dans le contenu des fichiers sur votre ordinateur. — Vous pouvez le voir comme un Google pour vos fichiers locaux. L'application fonctionne sur Windows, Linux et macOS. Elle est disponible sous licence Eclipse Public License.
Usage
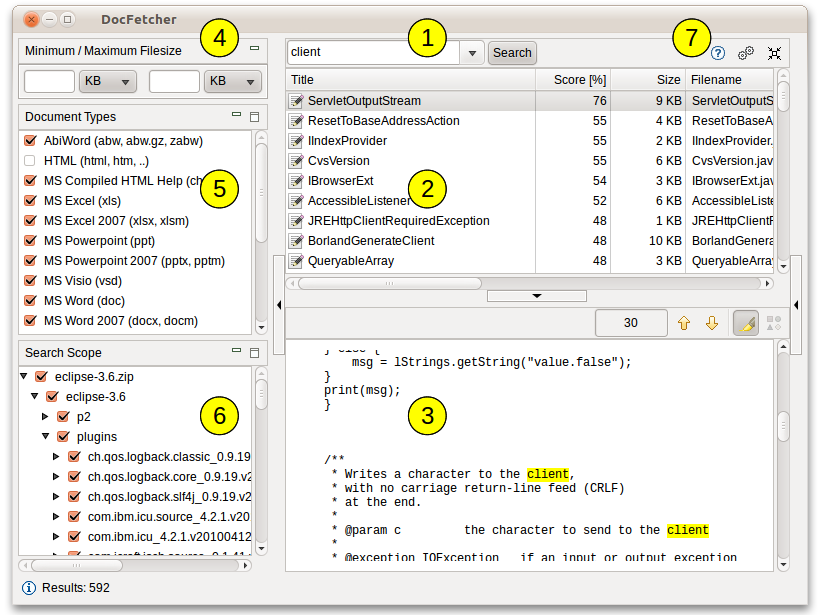
La capture d'écran ci dessous montre l'interface utilisateur principale. Les requêtes sont entrées dans le champ (1). Les résultats de la recherche apparaissent dans le panneau de résultat (2). Le panneau d'aperçu (3) montre seulement un aperçu du texte du fichier sélectionné dans le panneau résultat. Toutes les correspondances dans le fichiers sont surlignées en jaune.
Vous pouvez filtrer les résultats par taille minimale ou maximale (4), par type de fichier (5) et par emplacement (6). Les boutons (7) sont utilisés pour ouvrir le manuel, les menus de réglages et pour minimiser le programme dans la barre système.
DocFetcher a besoin que vous définissiez des index pour les dossiers dans lesquels vous voulez effectuer des recherches. Ce qu'est l'indexation et comment cela marche est expliqué plus en détails ci-dessous. En résumé, un index permet à DocFetcher de trouver très rapidement (on parle ici de millisecondes) quels fichiers contiennent un ensemble de mots, ainsi accélérant considérablement vos recherches. La capture d'écran qui suit montre la fenêtre de dialogue de DocFetcher pour créer de nouveaux index:
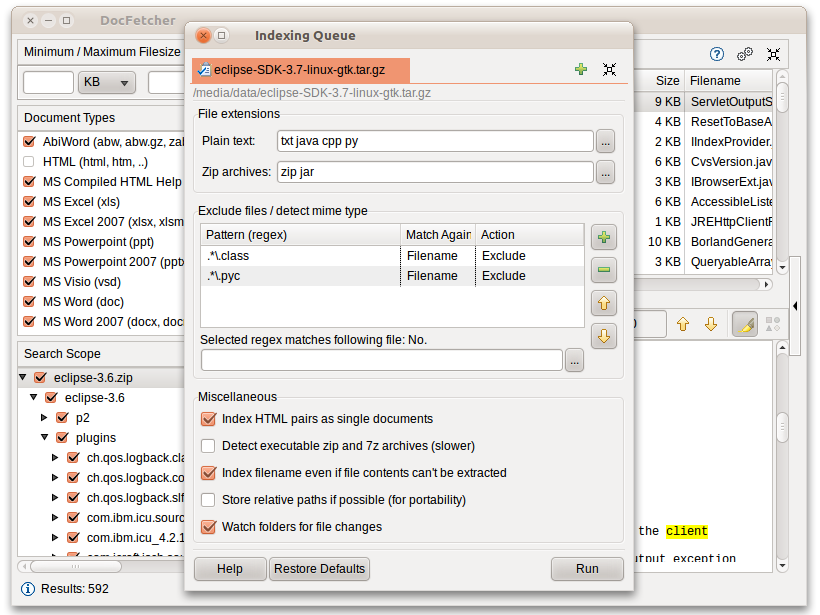
Cliquer sur le bouton "Démarrer" en bas à droite permet de commencer l'indexation. L'indexation peut durer un bon moment selon le nombre et la taille des fichiers qui doivent être indexés. En gros, il faut compter 200 fichiers par minute.
La création des index prend du temps mais elle n'a besoin d'être faite qu'une seule fois par dossier. De plus, mettre à jour un index après que son contenu ait changé est beaucoup plus rapide que de le créer — cela prend typiquement seulement quelques secondes.
Fonctions principales
- Versions portables: Il existe des versions portables de DocFetcher qui fonctionnent respectivement sur Windows, Linux et macOS. Ces versions portables vous permettent de créer un référentiel de documents portable: un référentiel entièrement indexé et entièrement interrogeable de tous vos documents importants que vous pouvez déplacer librement. Cela signifie que vous pouvez l'emporter sur une clé USB, l'emballer à des fins d'archivage, le placer dans un volume chiffré, le synchroniser entre plusieurs ordinateurs via un stockage cloud, ou même le télécharger et le partager avec le reste du monde.
- support Unicode support: DocFetcher vient avec un support Unicode robuste pour tous les formats principaux, incluant Microsoft Office, OpenOffice.org, PDF, HTML, RTF et les fichiers texte bruts. La seule exception est CHM, pour lequel il n'y a pas encore de support Unicode.
- Support des archives: DocFetcher supporte les formats d'archive suivants: zip, 7z, rar, et la famille complète des tar.*. Les extensions de fichiers peuvent être configurées afin de vous permettre d'ajouter plus de formats d'archives basés sur le format zip si nécessaire. De plus, DocFetcher gère un nombre illimité d'archives imbriquées (ex: une archive zip qui contient une archive 7z qui contient une archive rar... etc).
- Recherche dans les fichiers de code source: Les extensions que DocFetcher reconnait comme fichiers texte peuvent être configurées, de manière à ce que vous puissiez utiliser DocFetcher pour chercher n'importe quel type de fichier code source et de fichier basés sur du texte. (Ceci marche assez bien en combinaison avec la configuration des extensions zip par exemple pour chercher dans des fichiers code source à l'intérieur de fichiers Jar)
- Fichiers Outlook PST: DocFetcher permet de chercher les messages Outlook, que Microsoft Outlook stocke typiquement dans des fichiers PST.
- Détection de paires HTML : Par défaut, DocFetcher détecte les paires de fichiers HTML (ex: un fichier est nommé "toto.html" et un dossier "toto_files"), et les traite comme un document unique. Cette fonction peut paraître inutile de prime abord, mais cela augmente considérablement la qualité des résultats de recherche pour les fichiers HTML, dans la mesure ou tout le "bazar" dans le dossier HTML disparaît des résultats.
- exclusion de fichier à indexer basée des expressions régulières (Regex): vous pouvez utiliser des expression régulières pour exclure des fichiers de l'indexation. Par exemple, pour exclure des fichiers Microsoft Excel, vous pouvez utiliser une expression régulière comme ceci:
.*\.xls - Détection des types Mime: Vous pouvez utiliser des expressions régulières pour activer la détection du type mime pour certains fichiers, ce qui veut dire que DocFetcher essaiera de détecter le vrai type de fichier en pas seulement en se basant sur le nom mais aussi en regardant à l'intérieur. Ceci est utile pour les fichiers qui ont une mauvaise extension.
- Une syntaxe puissante pour les requêtes: en plus de constructions basiques comme et, ou et pas (
OR,ANDetNOT), DocFetcher supporte aussi entre autres: les caractères de remplacement, les recherches de phrase, les recherches floues ("trouver des mots similaires à..."), la recherche de proximité ("ces deux mots devraient être au plus à 10 mots d'intervalle l'un de l'autre"), "boosting" ("augmenter le score des documents qui contiennent...")
Formats de documents supportés
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 et versions plus récentes (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- HTML (html, xhtml, ...)
- Texte brut (configurable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Philosophie de conception
La conception de DocFetcher suit ces principes:
Sans bazar: L'interface de DocFetcher est conçue pour être simple et sans encombrement. Aucun élément inutile n'est installé dans votre système.
Vie privée: DocFetcher ne collecte pas vos données privées, point final. N'hésitez pas à vérifier le code source.
Indexez seulement ce dont vous avez besoin: D'autres logiciels de recherche indexent l'intégralité de votre disque dur par défaut — peut-être pour accommoder les utilisateurs "stupides", en prenant les décisions à leur place, ou pour récolter plus de données utilisateur. DocFetcher par contre n'indexe rien par défaut, laissant la sélection des données à indexer aux utilisateurs. Cela repose sur l'observation que l'indexation de disques durs entiers est généralement un énorme gaspillage de temps d'indexation et d'espace disque qui conduit également à un encombrement des résultats de recherche avec des fichiers non pertinents.
Comment fonctionne l'indexation
Cette section explique ce qu'est l'indexation et comment elle marche.
L'approche naïve pour la recherche de fichier: L'approche la plus basique pour la recherche de fichier est simplement de visiter chaque fichier dans un certain emplacement un par un à chaque fois qu'une recherche est effectuée. Cela marche assez bien pour une recherche uniquement par nom de fichier, car analyser les noms de fichiers est très rapide. Cependant, cela ne marcherait pas aussi bien si vous vouliez chercher le contenu des fichiers, car l'extraction de texte intégral est une opération bien plus coûteuse que l'analyse de nom de fichier.
Recherche basée sur un index: C'est pourquoi DocFetcher, qui permet de chercher le contenu, utilise une approche connue sous le nom d'indexation: l'idée de base est que la plupart des fichiers que les gens ont besoin de rechercher (typiquement plus de 95%) sont modifiés très rarement ou pas du tout. Donc, plutôt que d'extraire le texte complet de chaque fichier à chaque recherche, il est beaucoup plus efficace de faire l'extraction de texte sur tous les fichiers une seule fois, et de créer un index à partir de tout le texte extrait. Cet index est comme un dictionnaire qui permet de rechercher rapidement des fichiers par les mots qu'ils contiennent.
Analogie d'un annuaire: Comme analogie, considérez combien il est plus efficace de trouver le numéro de téléphone de quelqu'un dans l'annuaire (l'"index"), comparé au fait d'appeler chaque numéro possible juste pour voir si la personne de l'autre côté est celle que vous recherchez. — Appeler quelqu'un au téléphone et extraire le texte d'un fichier peuvent tous deux être considérés comme des "opérations coûteuses". De plus, le fait que les gens ne changent pas fréquemment leur numéro de téléphone est similaire au fait que la plupart des fichiers sur un ordinateur sont rarement modifiés.
Mises à jour de l'index: Bien sûr, un index ne reflète que l'état des fichiers indexés au moment de sa création, et pas nécessairement l'état le plus récent des fichiers. Ainsi, si l'index n'est pas conservé à jour, vous pourriez obtenir des résultats de recherche périmés, de la même manière qu'un annuaire peut devenir obsolète. Toutefois, ceci ne devrait pas être un gros problème si nous pouvons supposer que la plupart des fichiers sont rarement modifiés. De plus, DocFetcher est capable de mettre à jour automatiquement ses index: (1) Quand il est en cours d'exécution, il détecte les fichiers modifiés et met à jour ses index en conséquence. (2) Quand il n'est pas en cours d'exécution, un petit daemon en arrière-plan détecte les changements et garde une liste des index à mettre à jour; DocFetcher mettra ensuite à jour ces index lors du prochain démarrage.








