Nota: Puede que esté interesado en DocFetcher Pro, el hermano mayor comercial de DocFetcher con más características, o DocFetcher Server, el primo comercial de DocFetcher con soporte multiusuario y una interfaz web. Más información.
Descripción
DocFetcher es una aplicación de código abierto de búsqueda de escritorio: Permite que busques contenidos de ficheros en tu ordenador. — Puedes verlo como una especie de Google para tus ficheros locales. La aplicación funciona en Windows, Linux y macOS, y está disponible bajo la Licencia Eclipse Public.
Uso Básico
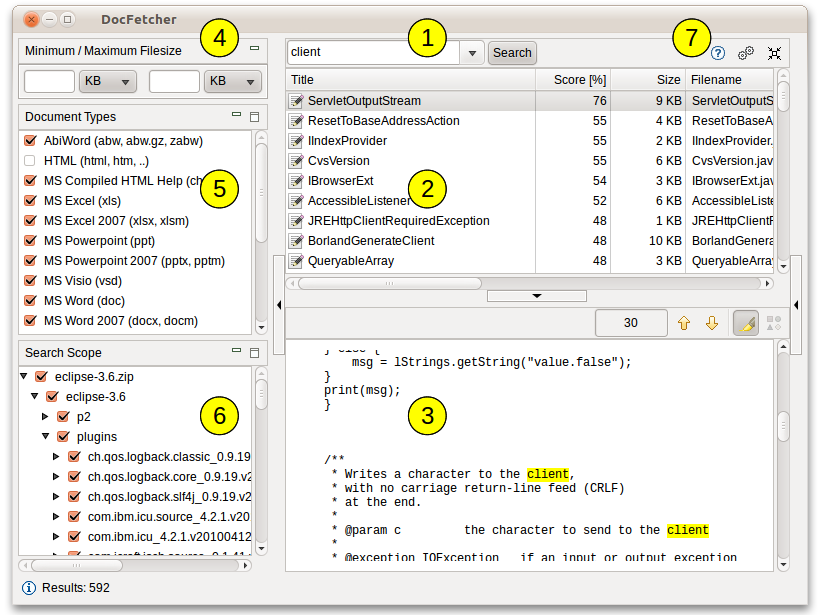
La siguiente captura de pantalla muestra el interfaz de usuario principal. Las consultas se introducen en el campo (1). Los resultados de la búsqueda se muestran en el panel de resultados (2). El panel de vista previa (3) muestra una versión sin formato (sólo texto) del fichero seleccionado in el panel de resultados. Todas las coincidencias en el archivo están resaltadas en amarillo.
Puede filtrar los resultados por el tamaño máximo y/o mínimo del fichero (4), por tipo de fichero (5) y por ubicación (6). Los botones en (7) sirven para abrir el manual, las preferencias y para minimizar el programa a la barra de tareas respectivamente.
DocFetcher necesita los llamados índices para las carpetas en las que quieras realizar búsquedas. Qué indexa y cómo lo hace está explicado en detalle más abajo. En pocas palabras, un índice le permite a DocFetcher buscar muy rápido (del orden de milisegundos) qué ficheros contienen unas palabras concretas, acelerando enormemente la velocidad de las búsquedas. Las siguientes capturas de pantalla muestran el cuadro de diálogo de DocFetcher para crear nuevos índices:
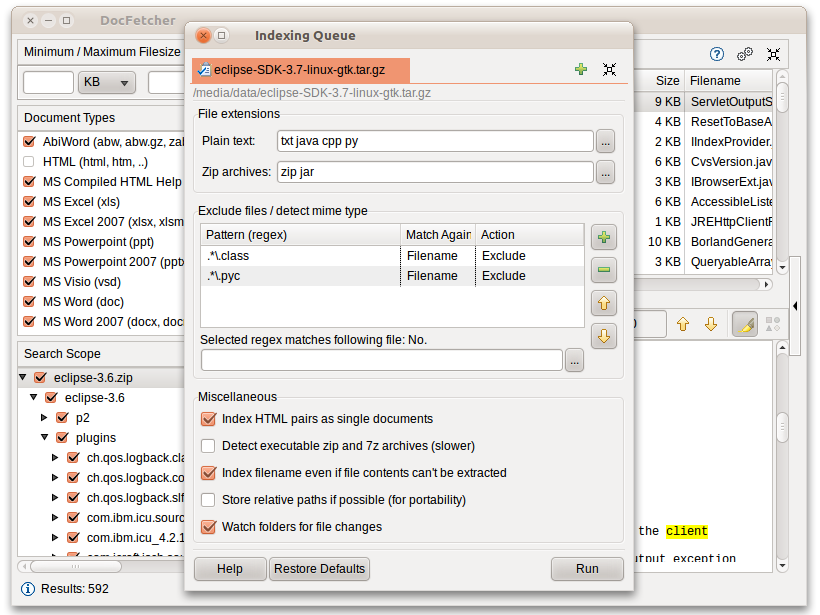
Pulsar el botón "Ejecutar" en la parte inferior derecha del cuadro de diálogo pone en marcha la indexación. El proceso de indexación puede tardar un rato, dependiendo del número y el tamaño de los ficheros a indexar. Aproximadamente podría procesar unos 200 ficheros por minuto.
Aunque tarda tiempo en crear el índice, sólo hay que hacerlo una vez por carpeta. *Actualizar" un índice cuando cambian los contenidos de la carpeta es mucho más rápido que crearlo — normalmente solo tarda un par de segundos.
Características Destacadas
- Versiones portables: Hay versiones portables de DocFetcher que funcionan en Windows, Linux y macOS, respectivamente. Estas versiones portables le permiten crear un repositorio de documentos portable: un repositorio totalmente indexado y completamente buscable de todos sus documentos importantes que puede mover libremente. Esto significa que puede llevarlo consigo en una unidad USB, empaquetarlo para fines de archivo, colocarlo en un volumen encriptado, sincronizarlo entre múltiples ordenadores a través de una unidad en la nube, o incluso cargarlo y compartirlo con el resto del mundo.
- Soporte Unicode: DocFetcher tiene un sólido soporte Unicode para los formatos más importantes, incluyendo Microsoft Office, OpenOffice.org, PDF, HTML, RTF y ficheros de texto plano.
- Ficheros soportados: DocFetcher soporta los siguientes formatos de fichero: zip, 7z, rar, y toda la familia tar.*. Las extensiones de los ficheros zip se pueden modificar, permitiendo así añadir más ficheros en formato zip según sea necesario. DocFetcher también puede gestionar un número ilimitado de ficheros anidados (por ejemplo, un fichero zip que contiene un fichero 7z que contiene a su vez un fichero rar, y así sucesivamente).
- Búsqueda en ficheros de código fuente: Las extensiones que DocFetcher reconoce como ficheros de texto plano se pueden modificar, por lo que puedes usar DocFetcher para buscar cualquier tipo de código fuente y otros tipos de ficheros en formato de texto plano. (Esto funciona muy bien en combinación con las extensiones zip modificables, por ejemplo, para buscar código fuente de Java dentro de ficheros .jar).
- Ficheros PST de Outlook: DocFetcher permite la búsqueda de correos electrónicos de Outlook, los cuales Microsoft Outlook normalmente almacena en ficheros PST.
- Detección de pares HTML: Por defecto, DocFetcher detecta los pares de ficheros HTML (por ejemplo, un fichero llamado "foo.html" y una carpeta llamada "foo_files"), y trata los pares como un único documento. Esta característica puede parecer poco útil al principio, pero como resultado se incrementa enormemente la calidad de las búsquedas al trabajar con ficheros HTML, ya que el "lío" dentro de las carpetas HTML desaparece de los resultados.
- Exclusión de ficheros de la indexación basada en regex: Puede usar expresiones regulares para excluir ciertos ficheros de la indexación. Por ejemplo, para excluir ficheros de Microsoft Excel, puede usar una expresión regular como esta:
.*\.xls - Detección de tipo mime: Puede usar expresiones regulares para activar la "detección de tipo mime" para ciertos ficheros, de manera que DocFetcher tratará de detectar el tipo de ficheros no sólo por el nombre de fichero, sino también comprobando el contenido del fichero. Esto resulta útil para ficheros que tienen una extensión incorrecta.
- Potente sintaxis de consulta: Además de las construcciones básicas como
OR,ANDyNOT, DocFetcher también soporta, entre otras cosas: Comodines, búsqueda de frases, búsquedas vagas ("buscar palabras que son similares a..."), búsqueda de proximidad ("estas dos palabras deben estar al menos separadas por 10 palabras"), incrementos ("incrementar la calificación de los documentos que contienen...")
Formatos de Documentos Soportados
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 and newer (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- HTML (html, xhtml, ...)
- Texto plano (customizable)
- Formato de Texto Enriquecido (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Filosofía de Diseño
El diseño de DocFetcher sigue estos principios:
Libre de estupideces: El interfaz de usuario de DocFetcher está diseñado para estar libre de líos y estupideces. Sin cosas inútiles instaladas en su sistema.
Privacidad: DocFetcher no recopila tu información privada, punto. Siéntete libre de consultar el código fuente.
Indexando sólo lo que necesita: Otro software de búsqueda indexa todo su disco duro por defecto — quizá para acomodar a usuarios "torpes", quitándoles las decisiones, o para recopilar más datos de usuario. DocFetcher, por otro lado, indexa nada por defecto, dejando la selección de datos a indexar a los usuarios. Esto se basa en la observación de que indexar discos duros completos es normalmente un enorme derroche de tiempo de indexación y espacio de disco que también conduce a una saturación de los resultados de búsqueda con ficheros irrelevantes.
Cómo Funciona La Indexación
Esta sección explica qué es la indexación y cómo funciona.
El enfoque ingenuo para la búsqueda de ficheros: El enfoque más básico para la búsqueda de ficheros es simplemente visitar cada fichero en una ubicación determinada uno por uno cada vez que se realiza una búsqueda. Esto funciona bastante bien para la búsqueda solo por nombre de fichero, porque analizar nombres de ficheros es muy rápido. Sin embargo, no funcionaría tan bien si quisieras buscar en el contenido de los ficheros, ya que la extracción de texto completo es una operación mucho más costosa que el análisis del nombre de fichero.
Búsqueda basada en índice: Por eso DocFetcher, siendo un buscador de contenido, adopta un enfoque conocido como indexación: La idea básica es que la mayoría de los ficheros que la gente necesita buscar (como, más del 95%) se modifican muy raramente o nunca. Por lo tanto, en lugar de realizar la extracción de texto completo en cada fichero en cada búsqueda, es mucho más eficiente realizar la extracción de texto en todos los ficheros solo una vez, y crear un llamado índice de todo el texto extraído. Este índice es algo así como un diccionario que permite buscar rápidamente ficheros por las palabras que contienen.
Analogía de la guía telefónica: Como analogía, considere lo mucho más eficiente que es buscar el número de teléfono de alguien en una guía telefónica (el "índice"), en comparación con llamar a todos los números de teléfono posibles solo para averiguar si la persona al otro lado es la que está buscando. — Llamar a alguien por teléfono y extraer texto de un fichero pueden considerarse ambas "operaciones costosas". Además, el hecho de que las personas no cambien sus números de teléfono con frecuencia es análogo al hecho de que la mayoría de los ficheros en un ordenador rara vez se modifican.
Actualizaciones del índice: Por supuesto, un índice solo refleja el estado de los ficheros indexados cuando se creó, no necesariamente el estado más reciente de los ficheros. Por lo tanto, si el índice no se mantiene actualizado, podría obtener resultados de búsqueda desactualizados, de la misma manera que una guía telefónica puede quedar obsoleta. Sin embargo, esto no debería ser un gran problema si podemos asumir que la mayoría de los ficheros rara vez se modifican. Además, DocFetcher es capaz de actualizar sus índices automáticamente: (1) Cuando está ejecutándose, detecta ficheros modificados y actualiza sus índices en consecuencia. (2) Cuando no está ejecutándose, un pequeño demonio en segundo plano detectará cambios y mantendrá una lista de índices a actualizar; DocFetcher luego actualizará esos índices la próxima vez que se inicie.








