Hinweis: Sie könnten Interesse haben an DocFetcher Pro, dem kommerziellen großen Bruder von DocFetcher mit mehr Features, oder DocFetcher Server, dem kommerziellen Cousin von DocFetcher für multiple Benutzer und mit einer web-basierten Benutzer-Oberfläche. Mehr dazu.
Beschreibung
DocFetcher ist ein Open-Source-Desktop-Suchprogramm: Es ermöglicht die Volltext-Suche in Dateien auf dem Computer — eine Art Google für den Heimrechner. Das Programm läuft auf Windows, Linux und macOS, und ist verfügbar unter der Eclipse Public License.
Grundlegende Benutzung
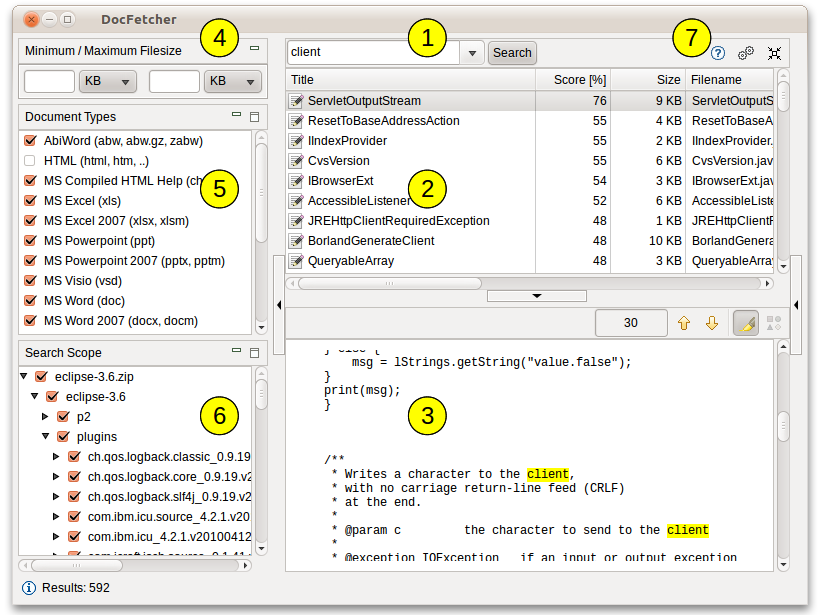
Der folgende Screenshot zeigt das Programm-Hauptfenster. Suchanfragen werden in das Textfeld bei (1) eingegeben. Die Suchergebnisse werden dann in der Ergebnis-Tabelle bei (2) angezeigt. Das Vorschau-Fenster bei (3) zeigt eine Text-Vorschau derjenigen Datei, die gegenwärtig in der Ergebnis-Tabelle selektiert ist. Alle Fundstellen in der Datei sind gelb hervorgehoben.
Sie können die Ergebnisse filtern nach Mindest- und/oder Maximal-Dateigröße (4), nach Datei-Typ (5) und nach Ort (6). Mit den Buttons bei (7) werden das Benutzer-Handbuch geöffnet, das Einstellungs-Fenster geöffnet, sowie das Programm in den System Tray minimiert.
DocFetcher erfordert das Erstellen sogenannter Indizes für die Ordner, die durchsucht werden sollen. Was Indizierung ist und wie es funktioniert, ist weiter unten erklärt. Grob gesagt erlaubt ein Index, sehr schnell (im Millisekunden-Bereich) herauszufinden, welche Dateien bestimmte Wörtern enthalten, wodurch sich die Suchgeschwindigkeit drastisch erhöht. Der folgende Screenshot zeigt DocFetcher's Dialog zum Erstellen neuer Indizes:
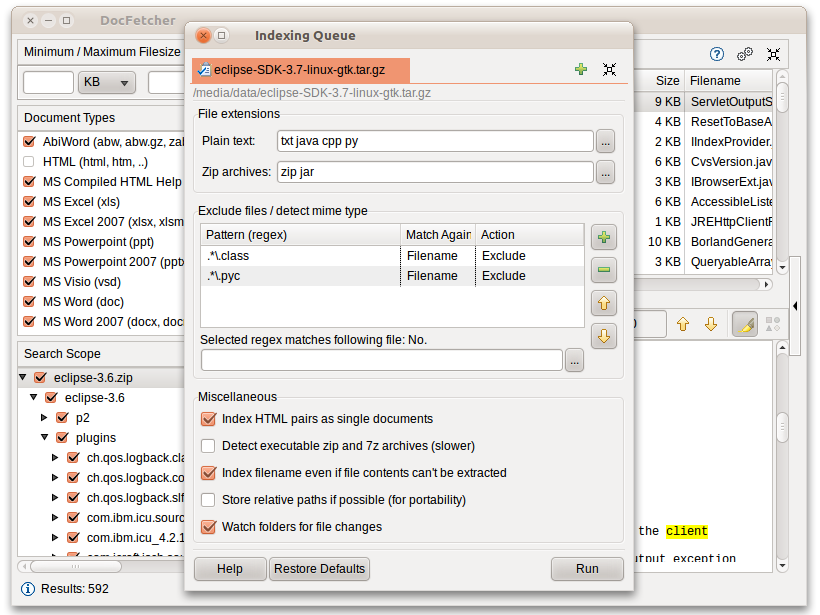
Durch Klicken auf den "Run"-Button unten rechts auf diesem Dialog wird die Indizierung gestartet. Die Indizierung kann in Abhängigkeit von der Anzahl und Größe der Dateien eine Weile dauern. Eine gute Daumenregel ist 200 Dateien pro Minute.
Das Erstellen eines Index mag zwar eine Weile dauern, aber dies muss nur einmal pro Ordner ausgeführt werden. Zudem läuft die Aktualisierung eines Index nach Veränderungen im dazugehörigen Ordner wesentlich schneller ab — üblicherweise dauert eine Aktualisierung lediglich einige Sekunden.
Besondere Features
- Portable Versionen: DocFetcher ist in portablen Versionen erhältlich, die auf Windows, Linux und macOS laufen. Diese portablen Versionen ermöglichen es Ihnen, ein portables Dokument-Repository zu erstellen: ein vollständig indiziertes und durchsuchbares Repository all Ihrer wichtigen Dokumente, das Sie frei umherbewegen können. Das bedeutet, Sie können es auf einem USB-Stick mit sich führen, zwecks Archivierung verpacken, in einen verschlüsselten Datei-Container stecken, mittels eines Cloud-Speichers über mehrere Computer hinweg synchronisieren, oder es sogar hochladen und mit der übrigen Welt teilen.
- Unicode-Unterstützung: DocFetcher bietet solide Unicode-Unterstützung für die gängigsten Datei-Formate, einschließlich Microsoft Office, OpenOffice.org, PDF, HTML, RTF und Textdateien.
- Archiv-Unterstützung: DocFetcher kommt mit folgenden Archiv-Formaten klar: zip, 7z, rar, sowie die gesamte tar.*-Format-Familie. Die Datei-Erweiterungen für Zip-Dateien können angepasst werden, sodass Sie bei Bedarf weitere zip-basierte Datei-Formate hinzufügen können. Zudem kann DocFetcher mit einer beliebig tiefen Verschachtelung von Archiven umgehen (bspw. ein Zip-Archiv, das ein 7z-Archiv enthält, welches ein Rar-Archiv enthält, usw.).
- Suche in Quell-Code: Die Datei-Erweiterungen, anhand derer DocFetcher Textdateien identifiziert, können angepasst werden, sodass DocFetcher in jeglichen textbasierten Datei-Formaten suchen kann, insbesondere in Quell-Code. (Dies funktioniert gut in Kombination mit den anpassbaren Zip-Erweiterungen, z. B. zur Suche in Java-Quell-Code, der in Jar-Dateien verpackt ist.)
- Outlook PST-Dateien: DocFetcher erlaubt die Suche in Outlook-E-Mails, die Microsoft Outlook typischerweise in PST-Dateien ablegt.
- Detektion von HTML-Paaren: Standardmäßig detektiert DocFetcher Paare von HTML-Dateien (z. B. eine Datei namens "Beispiel.html" und einen Ordner namens "Beispiel-Dateien"), und behandelt beides als ein einziges Dokument. Dieses Feature mag auf den ersten Blick nutzlos erscheinen; jedoch hat sich in der Praxis gezeigt, dass dies signifikant die Suchergebnisse verbessert, da nämlich der ganze "Müll" in den HTML-Ordnern aus den Suchergebnissen verschwindet.
- Datei-Ausschluss mittels regulärer Ausdrücke: Sie können mittels regulärer Ausdrücke bestimmte Dateien von der Indizierung ausschließen. Bspw. können Sie mit folgendem regulären Ausdruck alle Microsoft-Excel-Dateien von der Indizierung ausschließen:
.*\.xls - MIME-Typ-Detektion: Sie können mittels regulärer Ausdrücke eine "MIME-Typ-Detektion" für bestimmte Dateien einschalten. Dies bewirkt, dass DocFetcher deren tatsächlichen Datei-Typ dann nicht mehr nur anhand der Datei-Erweiterung, sondern auch durch Inspektion des Datei-Inhalts zu bestimmen versucht. Dies ist nützlich bei Dateien, denen eine falsche Datei-Erweiterung gegeben wurde.
- Mächtige Suchanfrage-Syntax: Über simple Konstrukte wie
OR,ANDundNOThinaus unterstützt DocFetcher unter Anderem: Wildcards, Phrasen-Suche, Fuzzy-Suche ("finde Wörter, die folgenden Wörtern ähneln: ..."), Nachbarschafts-Suche ("folgende Wörter sollen höchstens 10 Wörter voneinander entfernt sein"), Boosting ("gib Dateien höheres Gewicht, die folgende Wörter enthalten: ...")
Unterstützte Datei-Formate
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 und neuere Versionen (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, ...)
- TXT und andere Textdatei-Formate (anpassbar)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3-Metadaten (mp3)
- FLAC-Metadaten (flac)
- JPEG-Exif-Metadaten (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
Design-Philosophie
Das Design von DocFetcher folgt diesen Prinzipien:
Frei von Müll: DocFetcher's Benutzeroberfläche ist darauf ausgelegt, frei von Müll zu sein. Es wird kein nutzloses Zeug in Ihrem System installiert.
Privatsphäre: DocFetcher sammelt keine persönlichen Benutzerdaten, Punkt. Sie können gerne den Quell-Code überprüfen.
Nur indizieren, was nötig ist: Andere Such-Software indiziert Ihre gesamte Festplatte standardmäßig — möglicherweise um "dumme" Benutzer zu bedienen, indem ihnen Entscheidungen abgenommen werden, oder um mehr persönliche Benutzerdaten zu sammeln. DocFetcher hingegen indiziert standardmäßig nichts und überlässt die Auswahl der zu indizierenden Daten den Benutzern. Dies basiert auf der Beobachtung, dass die Indizierung ganzer Festplatten in der Regel eine enorme Verschwendung von Indizierungs-Zeit und Festplatten-Speicher ist, die auch zu einer Überfrachtung der Suchergebnisse mit irrelevanten Dateien führt.
Wie Indizierung funktioniert
Dieser Abschnitt erklärt, was Indizierung ist und wie es funktioniert.
Der naive Ansatz der Datei-Suche: Der einfachste Ansatz, nach Dateien zu suchen, besteht darin, bei jeder Suche alle Dateien nacheinander durchzugehen. Dies funktioniert prima für Suche, die sich auf Dateinamen beschränkt, da das Auslesen von Dateinamen sehr schnell vonstatten geht. Dieser Ansatz funktioniert jedoch nicht mehr so gut, wenn es darum geht, Datei-Inhalte zu durchsuchen, da nämlich die dazu erforderliche Text-Extraktion wesentlich mehr System-Ressourcen und Rechenzeit erfordert.
Index-basierte Suche: Das ist der Grund, warum DocFetcher, ein Suchprogramm für Datei-Inhalte, den Ansatz der Indizierung gewählt hat. Die Grundidee besteht darin, dass der Großteil der Dateien, in denen gesucht werden soll (z. B. über 95%), sehr selten oder überhaupt nicht modifiziert wird. Deshalb kann man darauf verzichten, bei jeder Suchanfrage eine volle Text-Extraktion vorzunehmen, und stattdessen diese Text-Extraktion nur einmal vornehmen, um daraus einen sogenannten Index zu erstellen. Einen solchen Index kann man sich vorstellen als eine Art Nachschlagewerk, welches erlaubt, zu einem gegebenen Wort schnell herauszufinden, welche Dateien dieses Wort enthalten.
Telefonbuch-Analogie: Als anschauliche Analogie möge man sich vergegenwärtigen, dass es wesentlich effizienter ist, die Telefonnummer einer bestimmten Person in einem Telefonbuch (dem "Index") nachzuschlagen, anstatt jede mögliche Telefonnummer auszuprobieren, nur um jeweils herauszufinden, ob die Person am anderen Ende der Leitung diejenige ist, nach der man sucht. — Jemanden über das Telefon anzurufen und die Text-Extraktion aus einer Datei sind beide "teure" Operationen. Außerdem ist der Fakt, dass Leute ihre Telefonnummern selten ändern, analog zu dem Fakt, dass die meisten Dateien auf einem Computer sehr selten, wenn überhaupt, modifiziert werden.
Index-Aktualisierung: Offenbar reflektiert ein Index nur den Zustand der indizierten Dateien zu dem Zeitpunkt, zu dem der Index erstellt wurde, und nicht zwangsläufig den aktuellen Zustand der Dateien. Das bedeutet, dass wenn der Index nicht auf dem neuesten Stand ist, die Suchergebnisse veraltet sein könnten, in derselben Weise wie auch Einträge in einem Telefonbuch veraltet sein könnten. Jedoch sollte dies kein großes Problem darstellen, wenn sich die Dateien selten ändern. Außerdem ist DocFetcher in der Lage, automatisch seine Indizes zu aktualisieren: (1) Während das Programm läuft, kann es Datei-Modifikationen detektieren und die Indizes entsprechend aktualisieren. (2) Wenn das Programm nicht läuft, detektiert ein kleines Daemon-Programm im Hintergrund Datei-Modifikationen und hält eine Liste von Indizes, die beim nächsten Ausführen von DocFetcher aktualisiert werden müssen.








